扫码一下
查看教程更方便
pandas dataframe是一种二维数据结构,数据在行和列中以表格方式对齐,可以认为就是一个表格。
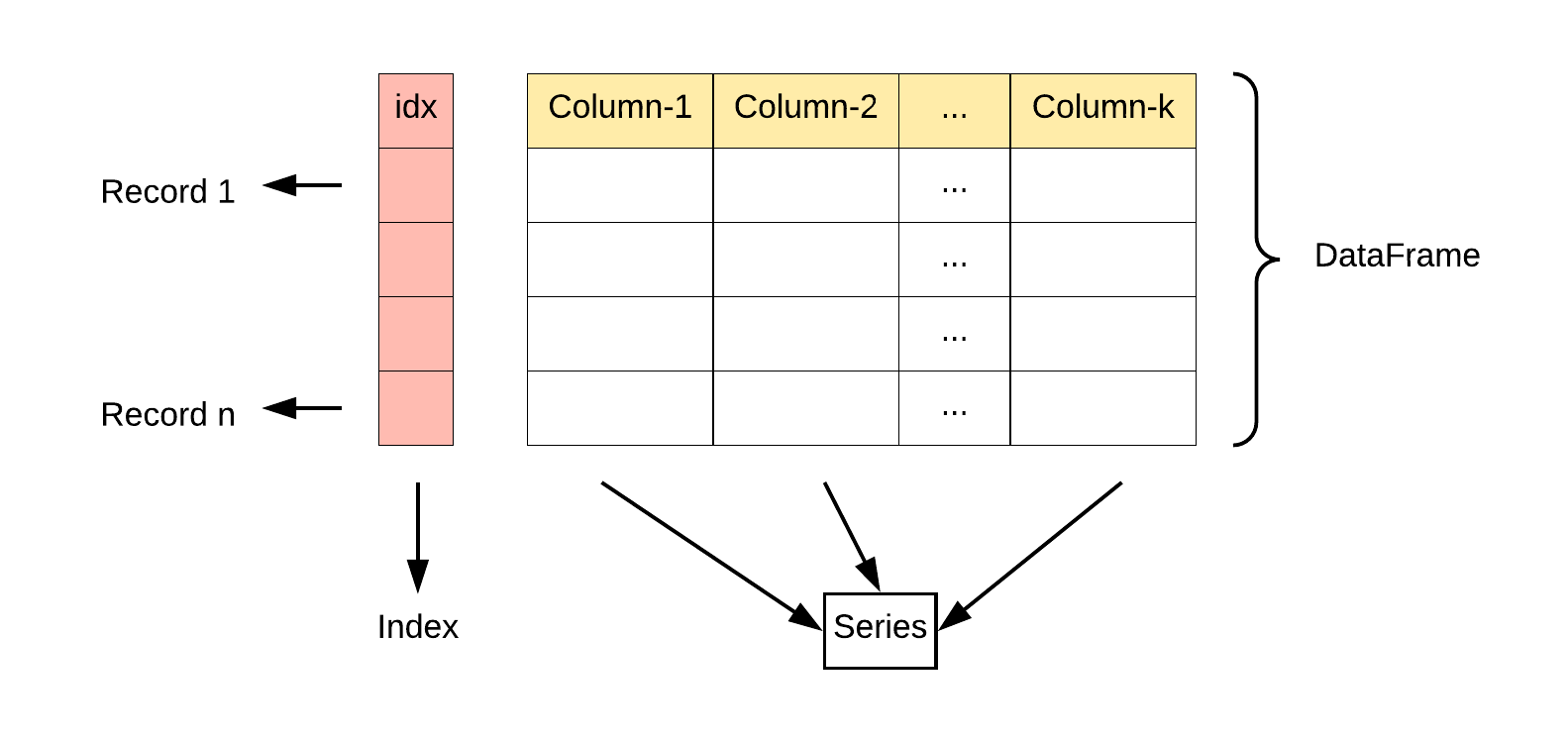
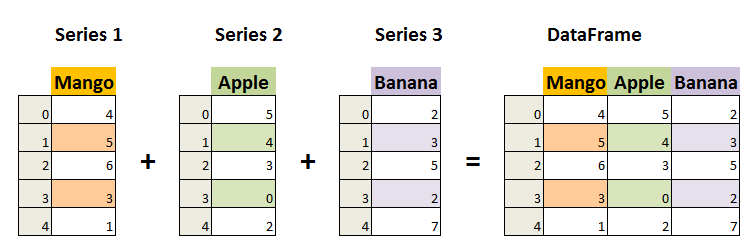
在pandas数据结构一节,我们说过在pandas中高维数据结构是其低维数据结构的容器。比如 dataframe 是 series 的容器。所以可以认为 dataframe数据是由多个series组成的
可以使用以下方法创建一个 dataframe 数据
pandas.dataframe( data, index, dtype, copy)
参数说明如下:
可以使用各种数据类型作为输入创建pandas dataframe
在本章的后续部分中,我们将看到如何使用这些输入创建 dataframe。
可以创建的最基本的 dataframe 是空 dataframe。
import pandas as pd
df = pd.dataframe()
print(df)
运行结果如下
empty dataframe
columns: []
index: []
可以使用单个列表或一组列表创建 dataframe。
import pandas as pd
#单个列表创建dataframe
data = [1,2,3,4,5]
single_df = pd.dataframe(data)
print(single_df)
#一组列表创建 dataframe
data = [['alex',10],['bob',12],['clarke',13]]
group_df = pd.dataframe(data,columns=['name','age'])
print(group_df)
运行结果如下
0
0 1
1 2
2 3
3 4
4 5
name age
0 alex 10
1 bob 12
2 clarke 13
接下来我们使用一组列表创建dataframe 并且指定 dtype
import pandas as pd
data = [['alex',10],['bob',12],['jiyik',13]]
df = pd.dataframe(data,columns=['name','age'],dtype=float)
print(df)
运行结果如下
name age
0 alex 10.0
1 bob 12.0
2 jiyik 13.0
注意- dtype参数将 age 列的类型更改为浮点数。但是在python3中对float类型有警告。
所有ndarray必须具有相同的长度。如果传递索引,则索引的长度应等于数组的长度。
如果未传递索引,则默认情况下,索引将为 range(n),其中n是数组长度。
import pandas as pd
#不指定索引
data = {'name':['tom', 'jack', 'steve', 'ricky'],'age':[28,34,29,42]}
df = pd.dataframe(data)
print(df)
#指定索引
index_df = pd.dataframe(data, index=['rank1','rank2','rank3','rank4'])
print(index_df)
运行结果如下
name age
0 tom 28
1 jack 34
2 steve 29
3 ricky 42
name age
rank1 tom 28
rank2 jack 34
rank3 steve 29
rank4 ricky 42
字典列表可以作为输入数据创建一个 dataframe。默认情况下,字典键作为列名。
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
#不指定索引
df = pd.dataframe(data)
print(df)
#指定行索引
row_index_df = pd.dataframe(data, index=['first', 'second'])
print(row_index_df)
#指定列行索引和列索引
column_index_df1 = pd.dataframe(data, index=['first', 'second'], columns=['a', 'b'])
print(column_index_df1)
#指定列行索引和列索引 不存在的列则默认使用 nan
column_index_df2 = pd.dataframe(data, index=['first', 'second'], columns=['a', 'b','c1'])
print(column_index_df2)
运行结果如下
a b c
0 1 2 nan
1 5 10 20.0
a b c
first 1 2 nan
second 5 10 20.0
a b
first 1 2
second 5 10
a b c1
first 1 2 nan
second 5 10 nan
注意- 观察,column_index_df2 dataframe 是使用字典键以外的列索引 c1 创建的;因此,该列显示 nan 。
可以传递 series 字典 来创建 dataframe。结果索引是所有传递的 series 索引的并集。
import pandas as pd
d = {'one' : pd.series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.dataframe(d)
print(df)
运行结果如下
one two
a 1.0 1
b 2.0 2
c 3.0 3
d nan 4
注意- 对于series one,没有标签“d”,但在结果中,对于d标签,则只能显示nan。
d = {'one' : pd.series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.dataframe(d)
print(df ['one'])
运行结果如下
a 1.0
b 2.0
c 3.0
d nan
name: one, dtype: float64
我们将通过向现有 dataframe 添加新列来理解该知识点。
import pandas as pd
d = {'one' : pd.series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.dataframe(d)
#向现有的dataframe添加一个新列
print ("adding a new column by passing as series:")
df['three']=pd.series([10,20,30],index=['a','b','c'])
print(df)
print ("adding a new column using the existing columns in dataframe:")
df['four']=df['one'] df['three']
print(df)
运行结果如下
adding a new column by passing as series:
one two three
a 1.0 1 10.0
b 2.0 2 20.0
c 3.0 3 30.0
d nan 4 nan
adding a new column using the existing columns in dataframe:
one two three four
a 1.0 1 10.0 11.0
b 2.0 2 20.0 22.0
c 3.0 3 30.0 33.0
d nan 4 nan nan
可以从dataframe中删除或弹出列;让我们举一个例子。
import pandas as pd
d = {'one' : pd.series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'three' : pd.series([10,20,30], index=['a','b','c'])}
df = pd.dataframe(d)
print ("our dataframe is:")
print(df)
#删除
print ("deleting the first column using del function:")
del df['one']
print(df)
#弹出
print ("deleting another column using pop function:")
df.pop('two')
print(df)
运行结果如下
our dataframe is:
one two three
a 1.0 1 10.0
b 2.0 2 20.0
c 3.0 3 30.0
d nan 4 nan
deleting the first column using del function:
two three
a 1 10.0
b 2 20.0
c 3 30.0
d 4 nan
deleting another column using pop function:
three
a 10.0
b 20.0
c 30.0
d nan
我们现在将通过示例了解行检索、添加和删除。
行的检索可以通过 标签、位置和切片的方式来进行
import pandas as pd
d = {'one' : pd.series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.dataframe(d)
#标签检索
print("access by label:")
print(df.loc['b'])
#位置索引
print("access by position:")
print(df.iloc[2])
#切片方式检索
print("access by slicing:")
print(df[2:4])
运行结果如下
access by label:
one 2.0
two 2.0
name: b, dtype: float64
access by position:
one 3.0
two 3.0
name: c, dtype: float64
access by slicing:
one two
c 3.0 3
d nan 4
使用append函数向 dataframe 添加新行。此函数将在末尾追加行。
import pandas as pd
df = pd.dataframe([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.dataframe([[5, 6], [7, 8]], columns = ['a','b'])
df = df.append(df2)
print(df)
运行结果如下
a b
0 1 2
1 3 4
0 5 6
1 7 8
使用索引标签从 dataframe 中删除行。如果标签重复,则将删除多行。
在上面的示例中,标签是重复的。让我们删除一个标签,看看有多少行会被删除。
import pandas as pd
df = pd.dataframe([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.dataframe([[5, 6], [7, 8]], columns = ['a','b'])
df = df.append(df2)
df = df.drop(0)
print(df)
运行结果如下
a b
1 3 4
1 7 8
在上面的示例中,删除了两行,因为这两行包含相同的标签 0。
