扫码一下
查看教程更方便
cgi 目前由 ncsa 维护,ncsa 定义 cgi 如下:
cgi(common gateway interface),通用网关接口,它是一段程序,运行在服务器上如:http 服务器,提供同客户端 html 页面的接口。
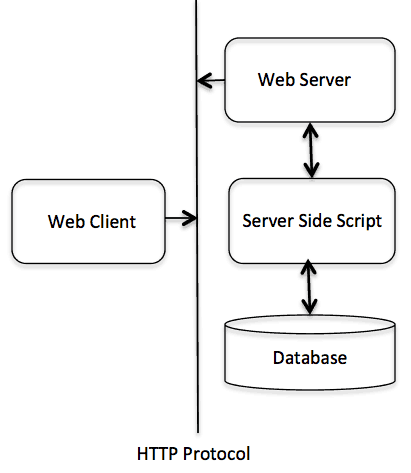
为了更好的了解 cgi 是如何工作的,我们可以从在网页上点击一个链接或 url 的流程:
cgi 程序可以是 python 脚本,perl 脚本,shell 脚本,c 或者 c 程序等。
在你进行 cgi 编程前,确保您的 web 服务器支持 cgi 及已经配置了 cgi 的处理程序。
apache 支持 cgi 配置:
设置好cgi目录:
scriptalias /cgi-bin/ /var/www/cgi-bin/
所有的http服务器执行 cgi 程序都保存在一个预先配置的目录。这个目录被称为 cgi 目录,并按照惯例,它被命名为 /var/www/cgi-bin 目录。
cgi 文件的扩展名为 .cgi,python 也可以使用 .py 扩展名。
默认情况下,linux 服务器配置运行的 cgi-bin 目录中为 /var/www。
如果你想指定其他运行 cgi 脚本的目录,可以修改 httpd.conf 配置文件,如下所示:
allowoverride none
options execcgi
order allow,deny
allow from all
在 addhandler 中添加 .py 后缀,这样我们就可以访问 .py 结尾的 python 脚本文件:
addhandler cgi-script .cgi .pl .py
我们使用 python 创建第一个 cgi 程序,文件名为 hello.py,文件位于 /var/www/cgi-bin 目录中,内容如下:
#!/usr/bin/python3
print ("content-type:text/html\r\n\r\n")
print ('')
print ('')
print ('hello world - first cgi program ')
print ('')
print ('')
print ('hello world! this is my first cgi program
')
print ('')
print ('')
文件保存后修改 hello.py,修改文件权限为 755:
$ chmod 755 hello.py
注意- 脚本中的第一行必须是 python 可执行文件的路径。在 linux 中它应该是 #!/usr/bin/python3
在浏览器中输入以下网址
http://localhost:8080/cgi-bin/hello.py
显示结果如下
hello world! this is my first cgi program
这个的hello.py脚本是一个简单的python脚本,脚本第一行的输出内容"content-type:text/html"发送到浏览器并告知浏览器显示的内容类型为"text/html"。
用 print 输出一个空行用于告诉服务器结束头部信息。
现在你应该已经了解了 cgi 的基本概念,并且可以使用 python 编写许多复杂的 cgi 程序。该脚本还可以与任何其他外部系统交互以交换信息,例如 rdbms。
hello.py文件内容中的" content-type:text/html"即为http头部的一部分,它会发送给浏览器告诉浏览器文件的内容类型。
http头部的格式如下:
http 字段名: 字段内容
例如:
content-type: text/html
以下表格介绍了cgi程序中http头部经常使用的信息:
| 头 | 描述 |
|---|---|
| content-type: | 请求的与实体对应的mime信息。例如: content-type:text/html |
| expires: | date 响应过期的日期和时间 |
| location: | url 用来重定向接收方到非请求url的位置来完成请求或标识新的资源 |
| last-modified: | date 请求资源的最后修改时间 |
| content-length: | n 请求的内容长度 |
| set-cookie: | string 设置http cookie |
所有的cgi程序都接收以下的环境变量,这些变量在cgi程序中发挥了重要的作用:
| 变量名 | 描述 |
|---|---|
| content_type | 这个环境变量的值指示所传递来的信息的mime类型。目前,环境变量content_type一般都是:application/x-www-form-urlencoded,他表示数据来自于html表单。 |
| content_length | 如果服务器与cgi程序信息的传递方式是post,这个环境变量即使从标准输入stdin中可以读到的有效数据的字节数。这个环境变量在读取所输入的数据时必须使用。 |
| http_cookie | 客户机内的 cookie 内容。 |
| http_user_agent | 提供包含了版本数或其他专有数据的客户浏览器信息。 |
| path_info | 这个环境变量的值表示紧接在cgi程序名之后的其他路径信息。它常常作为cgi程序的参数出现。 |
| query_string | 如果服务器与cgi程序信息的传递方式是get,这个环境变量的值即使所传递的信息。这个信息经跟在cgi程序名的后面,两者中间用一个问号'?'分隔。 |
| remote_addr | 这个环境变量的值是发送请求的客户机的ip地址,例如上面的192.168.1.67。这个值总是存在的。而且它是web客户机需要提供给web服务器的唯一标识,可以在cgi程序中用它来区分不同的web客户机。 |
| remote_host | 这个环境变量的值包含发送cgi请求的客户机的主机名。如果不支持你想查询,则无需定义此环境变量。 |
| request_method | 提供脚本被调用的方法。对于使用 http/1.0 协议的脚本,仅 get 和 post 有意义。 |
| script_filename | cgi脚本的完整路径 |
| script_name | cgi脚本的的名称 |
| server_name | 这是你的 web 服务器的主机名、别名或ip地址。 |
| server_software | 这个环境变量的值包含了调用cgi程序的http服务器的名称和版本号。例如,上面的值为apache/2.2.14(unix) |
以下是一个简单的cgi脚本输出cgi的环境变量:
#!/usr/bin/python3
import os
print ("content-type: text/html\r\n\r\n";)
print ("environment<\br>";)
for param in os.environ.keys():
print (" s: %s<\br>" % (param, os.environ[param]))
浏览器客户端通过两种方法向服务器传递信息,这两种方法就是 get 方法和 post 方法。
get方法发送编码后的用户信息到服务端,数据信息包含在请求页面的url上,以"?"号分割, 如下所示:
http://www.test.com/cgi-bin/hello.py?key1=value1&key2=value2
有关 get 请求的其他一些注释:
以下是一个简单的url,使用get方法向hello_get.py程序发送两个参数:
/cgi-bin/hello_get.py?web_name=迹忆客&tutorial=python
以下为hello_get.py文件的代码:
#!/usr/bin/python3
# import modules for cgi handling
import cgi, cgitb
# create instance of fieldstorage
form = cgi.fieldstorage()
# get data from fields
web_name = form.getvalue('web_name')
tutorial = form.getvalue('tutorial')
print ("content-type:text/html\r\n\r\n")
print ("")
print ("")
print ("hello - second cgi program ")
print ("")
print ("")
print ("hello %s %s
" % (web_name, tutorial))
print ("")
print ("")
文件保存后修改 hello_get.py,修改文件权限为 755:
$ chmod 755 hello_get.py
请求结果显示如下
hello 迹忆客 python
使用post方法向服务器传递数据是更安全可靠的,像一些敏感信息如用户密码等需要使用post传输数据。
以下同样是hello_get.py ,它也可以处理浏览器提交的post表单数据:
#!/usr/bin/python3
# import modules for cgi handling
import cgi, cgitb
# create instance of fieldstorage
form = cgi.fieldstorage()
# get data from fields
web_name = form.getvalue('web_name')
tutorial = form.getvalue('tutorial')
print ("content-type:text/html\r\n\r\n")
print ("")
print ("")
print ("hello - second cgi program ")
print ("")
print ("")
print ("hello %s %s
" % (web_name, tutorial))
print ("")
print ("")
以下为表单通过post方法(method="post")向服务器脚本 hello_get.py 提交数据:
checkbox用于提交一个或者多个选项数据,html代码如下:
以下为 checkbox.py 文件的代码:
#!/usr/bin/python3
# import modules for cgi handling
import cgi, cgitb
# create instance of fieldstorage
form = cgi.fieldstorage()
# get data from fields
if form.getvalue('maths'):
math_flag = "on"
else:
math_flag = "off"
if form.getvalue('physics'):
physics_flag = "on"
else:
physics_flag = "off"
print ("content-type:text/html\r\n\r\n")
print ("")
print ("")
print ("checkbox - third cgi program ")
print ("")
print ("")
print (" checkbox maths is : %s
" % math_flag)
print (" checkbox physics is : %s
" % physics_flag)
print ("")
print ("")
radio 只向服务器传递一个数据,html代码如下:
radiobutton.py 脚本代码如下:
#!/usr/bin/python3
# import modules for cgi handling
import cgi, cgitb
# create instance of fieldstorage
form = cgi.fieldstorage()
# get data from fields
if form.getvalue('subject'):
subject = form.getvalue('subject')
else:
subject = "not set"
print ("content-type:text/html\r\n\r\n")
print ("")
print ("")
print ("radio - fourth cgi program ")
print ("")
print ("")
print (" selected subject is %s
" % subject)
print ("")
print ("")
textarea 向服务器传递多行数据,html代码如下:
textarea.py 脚本代码如下:
#!/usr/bin/python3
# import modules for cgi handling
import cgi, cgitb
# create instance of fieldstorage
form = cgi.fieldstorage()
# get data from fields
if form.getvalue('textcontent'):
text_content = form.getvalue('textcontent')
else:
text_content = "not entered"
print ("content-type:text/html\r\n\r\n")
print ("")
print ("";)
print ("text area - fifth cgi program ")
print ("")
print ("")
print (" entered text content is %s
" % text_content)
print ("")
html 下拉框代码如下:
dropdown.py 脚本代码如下所示:
#!/usr/bin/python3
# import modules for cgi handling
import cgi, cgitb
# create instance of fieldstorage
form = cgi.fieldstorage()
# get data from fields
if form.getvalue('dropdown'):
subject = form.getvalue('dropdown')
else:
subject = "not entered"
print ("content-type:text/html\r\n\r\n")
print ("")
print ("")
print ("dropdown box - sixth cgi program ")
print ("")
print ("")
print (" selected subject is %s
" % subject)
print ("")
print ("")
在 http 协议一个很大的缺点就是不对用户身份的进行判断,这样给编程人员带来很大的不便, 而 cookie 功能的出现弥补了这个不足。
cookie 就是在客户访问脚本的同时,通过客户的浏览器,在客户硬盘上写入纪录数据 ,当下次客户访问脚本时取回数据信息,从而达到身份判别的功能,cookie 常用在身份校验中。
http cookie的发送是通过http头部来实现的,他早于文件的传递,头部set-cookie的语法如下:
set-cookie:name=name;expires=date;path=path;domain=domain;secure
domain="www.jiyik.com"cookie的设置非常简单,cookie会在http头部单独发送。以下实例在cookie中设置了name 和 expires:
#!/usr/bin/python3
print ("set-cookie:userid = xyz;\r\n")
print ("set-cookie:password = xyz123;\r\n")
print ("set-cookie:expires = tuesday, 31-dec-2015 23:12:40 gmt";\r\n")
print ("set-cookie:domain = www.jiyik.com;\r\n")
print ("set-cookie:path = /perl;\n")
print ("content-type:text/html\r\n\r\n")
...........rest of the html content....
以上实例使用了 set-cookie 头信息来设置cookie信息,可选项中设置了cookie的其他属性,如过期时间expires,域名domain,路径path。这些信息设置在 "content-type:text/html"之前。
cookie信息检索页非常简单,cookie信息存储在cgi的环境变量http_cookie中,存储格式如下:
key1=value1;key2=value2;key3=value3....
以下是一个简单的cgi检索cookie信息的程序:
#!/usr/bin/python
# import modules for cgi handling
from os import environ
import cgi, cgitb
if environ.has_key('http_cookie'):
for cookie in map(strip, split(environ['http_cookie'], ';')):
(key, value ) = split(cookie, '=');
if key == "userid":
user_id = value
if key == "password":
password = value
print ("user id = %s" % user_id)
print ("password = %s" % password)
这为上述脚本设置的 cookie 产生以下结果
user id = xyz
password = xyz123
html设置上传文件的表单需要设置 enctype 属性为 multipart/form-data,代码如下所示:
save_file.py脚本文件代码如下:
#!/usr/bin/python
import cgi, os
import cgitb; cgitb.enable()
form = cgi.fieldstorage()
# get filename here.
fileitem = form['filename']
# test if the file was uploaded
if fileitem.filename:
# strip leading path from file name to avoid
# directory traversal attacks
fn = os.path.basename(fileitem.filename)
open('/tmp/' fn, 'wb').write(fileitem.file.read())
message = 'the file "' fn '" was uploaded successfully'
else:
message = 'no file was uploaded'
print ("""\
content-type: text/html\n
%s
""" % (message,))
如果你使用的系统是unix/linux,你必须替换文件分隔符,在window下只需要使用open()语句即可:
fn = os.path.basename(fileitem.filename.replace("\\", "/" ))
我们先在当前目录下创建 foo.txt 文件,用于程序的下载。
文件下载通过设置http头信息来实现,功能代码如下:
#!/usr/bin/python
# http header
print ("content-type:application/octet-stream; name = \"filename\"\r\n";)
print ("content-disposition: attachment; filename = \"filename\"\r\n\n";)
# actual file content will go here.
fo = open("foo.txt", "rb")
str = fo.read();
print str
# close opend file
fo.close()
